Katakana
In der heutigen Welt bleibt Katakana ein grundlegendes und faszinierendes Thema, das die Aufmerksamkeit von Akademikern, Wissenschaftlern, Fachleuten und Enthusiasten gleichermaßen auf sich zieht. Die Bedeutung von Katakana zeigt sich in verschiedenen Bereichen, von der Medizin über die Technik bis hin zur Politik und Kultur. Im Laufe der Geschichte war Katakana Gegenstand von Studien und Debatten und zeigte seine Relevanz und Wirkung auf die Gesellschaft. In diesem Artikel werden wir verschiedene Aspekte im Zusammenhang mit Katakana untersuchen, von seinem Ursprung und seiner Entwicklung bis zu seinem aktuellen Einfluss, mit dem Ziel, einen umfassenden Überblick über dieses faszinierende und sich ständig verändernde Thema zu bieten.
| Katakana | ||
|---|---|---|
| Schrifttyp | Silbenschrift | |
| Sprachen | Japanisch Ainu Ryukyu Palauisch | |
| Verwendungszeit | seit ca. 800 n. Chr. | |
| Offiziell in | ||
| Abstammung | Chinesische Schrift → Man’yōgana → Katakana | |
| Verwandte | Hiragana, Hentaigana | |
| Unicodeblock | U+30A0..U+30FF | |
| ISO 15924 | Kana Hrkt (Hiragana und Katakana) Jpan (Hiragana, Katakana, Kanji) | |
  
| ||
Bei den Katakana (japanisch 片仮名 oder カタカナ) handelt es sich um eine Silbenschrift (genauer Morenschrift) der japanischen Sprache. Sie ist die zweite japanische Morenschrift neben den Hiragana. Außerdem werden in der japanischen Schrift noch chinesische Schriftzeichen verwendet, in diesem Kontext als Kanji bezeichnet.
Jedes Katakana-Zeichen steht als Syllabogramm entweder für einen Vokal oder für einen Konsonanten mit folgendem Vokal, mit der Ausnahme des später hinzugefügten Zeichens ン, das einen Nasallaut am Silbenende repräsentiert.
Die Katakana wurden aus chinesischen Schriftzeichen, genauer Man’yōgana, entwickelt, indem aus einem Zeichen mit der entsprechenden Lesung Striche weggelassen wurden. Katakana haben daher nur einen bis vier gerade oder leicht gebogene Striche und meist spitze Winkel und unterscheiden sich vom Schriftbild deutlich von den weichen, gerundeten Hiragana.
Die Katakana werden nach der 50-Laute-Tafel angeordnet. Das Iroha, ein Gedicht, in dem alle fünfzig ursprünglichen Silben vorkommen, wird stattdessen nur noch selten verwendet.
Silben- oder Morenschrift?
Im Japanischen ist die phonologisch maßgebliche suprasegmentale Einheit nicht die Silbe, sondern die More (z. B. werden im Haiku und im Tanka nicht die Silben gezählt, sondern die Moren). Japanische Moren bestehen aus einem Kurzvokal oder aus einem prävokalischen Konsonanten und einem Kurzvokal oder aus einem bloßen postvokalischen Konsonanten im Silbenausgang. Silben mit Langvokal oder mit postvokalischem Konsonanten im Silbenausgang sind zweimorig.
Diese silbenphonologische Eigenschaft des Japanischen wird auch in den Katakana und Hiragana berücksichtigt: pro More ein Schriftzeichen. Bei kurzvokalischen offenen Silben entspricht die More der Silbe (daher werden die japanischen Morenschriften oft auch ungenau als Silbenschriften bezeichnet).
Zur Darstellung eines Langvokals wird in der Katakana-Schreibung ein Diakritikon (der Chōonpu) gebraucht und in der Hiragana-Schreibung das Zeichen für den Kurzvokal doppelt gebraucht, so dass der erste „Kurzvokal“ zur ersten und der zweite zur zweiten More gehört. Ein postvokalischer Konsonant im Silbenausgang bildet für sich eine More und wird durch ein eigenes Schriftzeichen dargestellt. Eine zweisilbige Form muss so je nach der Zahl der Moren durch zwei, drei oder vier Zeichen dargestellt werden.
Tabelle
Einige Katakana-Zeichen sind recht ähnlich, da sie sich nur in der Richtung der kleinen Striche voneinander unterscheiden: シ shi und ツ tsu zum Beispiel oder ソ so und ン n. Die Unterschiede sind deutlicher zu erkennen, wenn die Symbole mit einem Schreibpinsel gezeichnet werden.
- Kursiv ist hinter dem Katakana die jeweilige Transkription nach Hepburn zu lesen.
- Grau sind Zeichen hervorgehoben, die veraltet sind oder nicht (mehr) vom MEXT aufgeführt werden.
- Unter dem Katakana befindet sich die Aussprache in IPA nach den Konventionen der englischen Wikipedia
Standard
| a | i | u | e | o | ya | yu | yo | ||
| Einzelgraphen (Gojūon) |
Digraphen (Yōon) | ||||||||
| ∅ | ア a |
イ i |
ウ u |
エ e |
オ o |
||||
| k | カ ka |
キ ki |
ク ku , |
ケ ke |
コ ko |
キャ kya |
キュ kyu |
キョ kyo | |
| s | サ sa |
シ shi , |
ス su , |
セ se |
ソ so |
シャ sha |
シュ shu |
ショ sho | |
| t | タ ta |
チ chi 8 |
ツ tsu , |
テ te |
ト to |
チャ cha |
チュ chu |
チョ cho | |
| n | ナ na |
ニ ni |
ヌ nu |
ネ ne |
ノ no |
ニャ nya |
ニュ nyu |
ニョ nyo | |
| h | ハ ha 1 |
ヒ hi , 6 |
フ fu |
ヘ he 1 |
ホ ho |
ヒャ hya , |
ヒュ hyu , |
ヒョ hyo , | |
| m | マ ma |
ミ mi |
ム mu |
メ me |
モ mo |
ミャ mya |
ミュ myu |
ミョ myo | |
| y | ヤ ya |
𛄠 yi 2 |
ユ yu |
𛄡 ye 2 |
ヨ yo |
||||
| r | ラ ra |
リ ri |
ル ru |
レ re |
ロ ro |
リャ rya |
リュ ryu |
リョ ryo | |
| w | ワ wa |
ヰ wi , 4 |
𛄢 wu , 2 |
ヱ we , 4 |
ヲ wo 3 , 4 |
||||
| * | ン n , , , 7 |
||||||||
| Einzelgraphen mit Diakritika (Gojūon mit Dakuten und Handakuten) |
Digraphen mit Diakritika (Yōon mit Dakuten und Handakuten) | ||||||||
| g | ガ ga |
ギ gi |
グ gu |
ゲ ge |
ゴ go |
ギャ gya |
ギュ gyu |
ギョ gyo | |
| z | ザ za |
ジ ji 5 |
ズ zu 5 |
ゼ ze |
ゾ zo |
ジャ ja |
ジュ ju |
ジョ jo | |
| d | ダ da |
ヂ ji/dji/jyi 5 , |
ヅ zu/dzu 5 , |
デ de |
ド do |
ヂャ ja/dja/jya 5 , |
ヂュ ju/dju/jyu 5 , |
ヂョ jo/djo/jyo 5 , | |
| b | バ ba |
ビ bi |
ブ bu |
ベ be |
ボ bo |
ビャ bya |
ビュ byu |
ビョ byo | |
| p | パ pa |
ピ pi |
プ pu |
ペ pe |
ポ po |
ピャ pya |
ピュ pyu |
ピョ pyo | |
- 1Wenn Katakana nicht für Fremdwörter, sondern für das Schreiben nativer japanischer Wörter verwendet werden und es sich bei ハ und ヘ um Partikel handelt (häufig zu sehen in Vorkriegsliteratur ( Rekishiteki Kanazukai)), wird ハ ha /ɰa/ und ヘ he dann /e/ ausgesprochen.
- 2Die Zeichen 𛄠 (
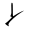 ) yi, 𛄡 (
) yi, 𛄡 (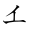 ) ye und 𛄢 (
) ye und 𛄢 ( ) wu erschienen in einigen Textbüchern ab 1873 (Meiji 6), waren aber niemals allgemein gebräuchlich. Für die digitale Anzeige dieser obsoleten Kana muss eine Schriftart installiert werden, die diese enthält. Dazu gehört z. B. Uraniwa Mincho X.
) wu erschienen in einigen Textbüchern ab 1873 (Meiji 6), waren aber niemals allgemein gebräuchlich. Für die digitale Anzeige dieser obsoleten Kana muss eine Schriftart installiert werden, die diese enthält. Dazu gehört z. B. Uraniwa Mincho X. - 4Die weiteren w-Katakana wurden früher auch zur Transkription des w-Lautes verwendet; so findet man heute noch ヰスキー wisukī /ɰisɯ̥ki/ für Whiskey. Heutzutage wird es aber präferiert, für die Darstellung des englischen w-Lautes die u-Kombinationen (ウォ vo, ウィvi und ウェ ve) zu verwenden. Häufig wird auch keine Kombination verwendet z. B. ウイザード uizādo anstelle von ウィザード wizādo für engl. "wizard".
- 5Die Kana ヂ ji and ヅ zu sind v. a. für etymologische Schreibweisen, wenn die stimmlosen Äquivalente チ chi und ツ tsu einer Lautverschiebung (Rendaku) unterzogen werden und stimmhaft werden, wenn sie in der Mitte eines zusammengesetzten Wortes auftreten, z. B. in ツヅク tsudzuku. In anderen Fällen werden stattdessen die identisch ausgesprochenen ジ ji and ズ zu verwendet. ヂ dji und ヅ dzu können niemals am Anfang eines Wortes stehen und sie sind im Katakana nicht üblich, da das Konzept von Rendaku nicht für transkribierte Fremdwörter gilt, eine der Hauptanwendungen von Katakana.
Je nach Region (Yotsugana) werden ジ, ヂ, ズ und ヅ anders ausgesprochen. Im Tokyoter Dialekt gilt: ヅ=ズ /(d)zɯ/ und ジ=ヂ /(d)ʑi/. - 6Im Tokyoter Dialekt wird ヒ hi anders ausgesprochen, je nachdem, wo es im Wort steht. Am Wortende und vor einem Obstruenten wird es /çi/, wie das „weiche ch“ in „Ich“, gesprochen (z. B. コーヒー kōhī /koːçiː/ oder ヒト hito /çito/), ansonsten /hi/ (z. B. ヒメ hime /hime/). Je nach Region wird ヒ hi aber auch unabhängig von der Wortstellung immer /çi/ ausgesprochen.
- 7Je nach Position im Wort wird ン n anders ausgesprochen. Vor m-, b- oder p-Kana wird es /m/ gesprochen (z. B. ナンバー nanbā /nambaː/), im Wort /ɴ/, am Ende meist /ñ/. /ɰ̃/ ist die Umschreibung für alle Aussprachevarianten.
- 8Der Laut /ti/ wird häufig mit ティ dargestellt. In älteren Werken wird häufig der nativ japanische Laut /ʨi/ für /ti/ substituiert. So heißt es häufiger チーム chīmu für engl. Team anstelle des phonetischen näheren ティーム tīmu.
Erweiterte Katakana (特殊音)
Die folgende Tabelle ist eine neuzeitliche Erweiterung moderner Zeichenzusammensetzungen (→Japanische Schrift#Palatalisierung – Brechung (Ligatur)), die ausschließlich der Aussprache fremdsprachiger Begriffe (→Gairaigo) dient.
- Mit einem ☆ sind alle Kombinationen markiert, die vom MEXT offiziell standardisiert wurden. Diese werden auch im japanischen Alltag verwendet und sind verwendungssicher.
- Mit einem ▢ sind alle Kombinationen markiert, die erstmals im 1974er Hyōjun-shiki standardisiert wurden. Diese Varianten sind aussprachesicher, werden aber kaum verwendet.
- Mit einem △ sind alle Kombinationen markiert, die vorwiegend in linguistischen Sammelwerken zur akkurateren Lautwiedergabe verwendet werden. Sie sind nicht verwendungssicher, da sie nicht standardisiert sind, d. h. Transkriptionen und Aussprachen variieren je nach Umsetzung. Den meisten Japanern sind diese nicht bekannt. → Listen (beispielhaft): 1, 2, 3
- Mit einem ◇ sind alle Kombinationen markiert, die zusätzlich von der British Standards Institution 1972 vorgeschlagen wurden. Einige inzwischen obsolete Kana sind dort noch enthalten, wie etwa ヰ wi und ヱ we oder auch die alten v-Kana ヷ va, ヸ vi, ヹ ve, ヺ vo.
- Mit einem ▣ sind alle Kombinationen markiert, die veraltet sind oder nicht vorwiegend für die Transkription von Fremdwörtern gebraucht werden.
| Gruppe | 行 | a | i | u | e | o |
|---|---|---|---|---|---|---|
| k-Gruppe | カ゚行 ng 1 |
カ゚ nga ▣ |
キ゚ ngi ▣ |
ク゚ ngu ▣ |
ケ゚ nge ▣ |
コ゚ ngo ▣ |
| s-Gruppe | サ行 s |
スィ swi/si 2 △▢ , |
||||
| セィ si 2 △ |
||||||
| サ行 sh |
シィ shi/shī △ |
シェ she ▢☆ |
||||
| ザ行 z |
ズィ zwi/zi 2 ▢ , |
|||||
| ゼィ zi 2 △ |
||||||
| ザ行 j |
ジィ ji/jī △ |
ジェ je ☆ |
||||
| t-Gruppe | タ行 t |
ティ ti ▢☆ |
トゥ tu 2 ▢☆ |
|||
| タ行 ch |
チィ chi/chī △ |
チェ che ☆ |
||||
| タ行 ts |
ツァ tsa ▢☆ |
ツィ tsi ▢☆ |
ツゥ tsu/tsū △ |
ツェ tse ▢☆ |
ツォ tso ▢☆ | |
| ダ行 d |
ディ di ▢☆ |
ドゥ du 2 ▢☆ |
||||
| ダ行 dj |
ヂィ dji/djī/jyi/jyī ▣△ , |
ヂェ dje/jye ▣△▢ , |
||||
| h-Gruppe | ハ行 h |
ホゥ hu △▢ |
||||
| ハ行 f |
ファ fa ▢☆ |
フィ fi ▢☆ |
フゥ fu/fū △ |
フェ fe ▢☆ |
フォ fo ▢☆ | |
| y-Gruppe | ヤ行 y |
イィ yi △▢ , |
イェ ye ▢☆ , |
|||
| ユェ ye △ , |
||||||
| r-Gruppe | ラ゚行 l 3 |
ラ゚ la ▣△▢ |
リ゚ li ▣△▢ |
ル゚ lu ▣△▢ |
レ゚ le ▣△▢ |
ロ゚ lo ▣△▢ |
| w-Gruppe | ワ行 w |
ウァ wa ◇△ |
ウィ wi ☆ |
ウゥ wu 2 △▢ , |
ウェ we ☆ |
ウォ wo ☆ |
| ヷ行 v 4 |
ヴァ va ▢☆ |
ヴィ vi ▢☆ |
ヴ vu ▢☆ |
ヴェ ve ▢☆ |
ヴォ vo ▢☆ | |
| ヷ va ▣△▢ |
ヸ vi ▣△▢ |
(5) vu ▣△▢ |
ヹ ve ▣△▢ |
ヺ vo ▣△▢ |
| Gruppe | 行 | a | i | u | e | o |
|---|---|---|---|---|---|---|
| k-Gruppe | カ行 ky |
キィ kyi △ |
キェ kye ◇ |
|||
| ガ行 gy |
ギィ gyi △ |
ギェ gye ◇ |
||||
| カ゚行 ngy |
キ゚ャ ngya ▣ |
キ゚ュ ngyu ▣ |
キ゚ョ ngyo ▣ | |||
| s-Gruppe | サ行 sy |
スャ sya △ |
スュ syu △ |
スョ syo △ | ||
| ザ行 zy |
ズャ zya △ |
ズュ zyu △ |
ズョ zyo △ | |||
| t-Gruppe | タ行 ty |
テャ tya △ |
テュ tyu ☆ |
テェ tye △ |
テョ tyo △ | |
| ティェ tye △ |
||||||
| タ行 tsy |
ツャ tsya △ |
ツュ tsyu ◇△ |
ツョ tsyo △ | |||
| ダ行 dy |
デャ dya △ |
デュ dyu ☆ |
デェ dye △ |
デョ dyo △ | ||
| ディェ dye △ |
||||||
| n-Gruppe | ナ行 ny |
ニィ nyi △ |
ニェ nye ◇ |
|||
| h-Gruppe | ハ行 hy |
ヒィ hyi △ , |
ヒェ hye ◇ , |
|||
| ハ行 fy |
フャ fya ◇△ , |
フュ fyu ☆ , |
フィェ fye ◇△ , |
フョ fyo ◇△ , | ||
| バ行 by |
ビィ byi △ |
ビェ bye ◇ |
||||
| パ行 py |
ピィ pyi △ |
ピェ pye ◇ |
||||
| m-Gruppe | マ行 my |
ミィ myi △ |
ミェ mye ◇ |
|||
| r-Gruppe | ラ行 ry |
リィ ryi △ |
リェ rye ◇ |
|||
| ラ゚行 ly |
リ゚ャ lya ▣△ |
リ゚ュ lyu ▣△ |
リ゚ョ lyo ▣△ | |||
| w-Gruppe | ワ行 wy |
ヰャ wya ▣△ |
ヰュ wyu ▣△ |
ヰョ wyo ▣△ | ||
| ウャ wya △ |
ウュ wyu ◇△ |
ウョ wyo △ | ||||
| ヷ行 vy |
ヴャ vya ◇△ |
ヴュ vyu ☆ |
ヴィェ vye ◇△ |
ヴョ vyo ◇△ |
| Gruppe | 行 | a | i | u | e | o |
|---|---|---|---|---|---|---|
| k-Gruppe | カ行 kw |
クァ kwa ☆ |
クィ kwi ☆ |
クゥ kwu △ |
クェ kwe ☆ |
クォ kwo ☆ |
| クヮ6 kwa ▣△ |
||||||
| ガ行 gw |
グァ gwa ☆ |
グィ gwi ◇△ |
グゥ gwu △ |
グェ gwe ◇△ |
グォ gwo ◇△ | |
| グヮ6 gwa ▣ |
||||||
| s-Gruppe | サ行 sw |
スァ swa △ |
スゥィ swi △ |
スゥ swu △ |
スェ swe △ |
スォ swo △ |
| ザ行 zw |
ズァ zwa △ |
ズゥィ zwi △ |
ズゥ zwu △ |
ズェ zwe △ |
ズォ zwo △ | |
| t-Gruppe | タ行 tw |
トァ twa △ |
トィ twi △ |
トェ twe △ |
トォ two △ | |
| トゥァ twa △ |
トゥィ twi △ |
トゥゥ twu △ |
トゥェ twe △ |
トゥォ two △ | ||
| ダ行 dw |
ドァ dwa △ |
ドィ dwi △ |
ドェ dwe △ |
ドォ dwo △ | ||
| ドゥァ dwa △ |
ドゥィ dwi △ |
ドゥゥ dwu △ |
ドゥェ dwe △ |
ドゥォ dwo △ | ||
| n-Gruppe | ナ行 nw |
ヌァ nwa △ |
ヌィ nwi △ |
ヌゥ nwu △ |
ヌェ nwe △ |
ヌォ nwo △ |
| h-Gruppe | ハ行 hw |
ホゥァ hwa △ |
ホゥィ hwi △ |
ホゥゥ hwu △ |
ホゥェ hwe △ |
ホゥォ hwo △ |
| バ行 bw |
ブァ bwa △ |
ブィ bwi △ |
ブゥ bwu △ |
ブェ bwe △ |
ブォ bwo △ | |
| パ行 pw |
プァ pwa △ |
プィ pwi △ |
プゥ pwu △ |
プェ pwe △ |
プォ pwo △ | |
| m-Gruppe | マ行 mw |
ムァ mwa △ |
ムィ mwi △ |
ムゥ mwu △ |
ムェ mwe △ |
ムォ mwo △ |
| r-Gruppe | ラ行 rw |
ルァ rwa △ |
ルィ rwi △ |
ルゥ rwu △ |
ルェ rwe △ |
ルォ rwo △ |
| w-Gruppe | ヷ行 vw |
ヴゥァ vwa △ |
ヴゥィ vwi △ |
ヴゥゥ vwu △ |
ヴゥェ vwe △ |
ヴゥォ vwo △ |
| Gruppe | 行 | a | i | u | e | o |
|---|---|---|---|---|---|---|
| h-Kombinationen | ||||||
| t-Gruppe | タ行 t/th |
テァ tha △ , |
テゥ thu/tu △ , |
テォ tho △ , | ||
| ダ行 d/dh |
デァ dha △ , |
デゥ dhu/du △ , |
デォ dho △ , | |||
| funktionale Grapheme | ||||||
| * | * | ヵ, ヶ 7 , , |
ー Chōonpu ☆ |
ッ Sokuon ☆ |
ヽ Kurikaeshi |
ヾ Kurikaeshi |
- 1Diese Kombinationen werden eigentlich nur in Hiragana verwendet und dienen der Anzeige des Bidakuon (鼻濁音). Zeitweise wurde darüber nachgedacht, mit diesem Kana ein ehemaliges c anzuzeigen. So wäre engl. "call" dann コ゚ール cōru statt コール kōru (ähnlich wie bei der L-Reihe). In der Praxis findet die Katakana-Version ng bzw. c keinerlei Anwendung mehr.
- 2Die Kombinationen スィ si, swi und ズィ zi, zwi existieren zwar, jedoch werden diese nicht gängig verwendet. Aus diesem Grund werden sie oft nicht in erweiterten Katakana-Tabellen aufgelistet. Ihre Aussprache ist ungesichert, so ist eine Aussprache als si wie in "Bassist" möglich, aber auch eine Aussprache als swi ähnlich wie in "Swing". Die aussprachesicheren Varianten セィ si und ゼィ zi, sowie スゥィ swi und ズゥィ zwi, werden noch wesentlich seltener eingesetzt und sind den meisten Japanern unbekannt. Sehr häufig wird si in der Transkription durch シ shi und zi durch ジ ji ersetzt. Die Kombination トゥ tu und ドゥ du existieren ebenso, werden aber häufig durch ツ tsu und ヅ dzu ersetzt, um Verwirrungen mit twu und dwu zu unterbinden. ウゥ wu gehört ebenfalls zu den nicht verwendungssicheren Kombinationen, da diese für Japaner schwieriger auszusprechen sind. Im Regelfall wird ウゥ wu deshalb mit ウー ū ersetzt.
- 3Die Kombinationen der L-Reihe werden oft noch in erweiterten Katakana-Tabellen gelistet. Sie werden jedoch in der Praxis nicht genutzt, da Kombinationen der L-Reihe wie Kombinationen der R-Reihe ausgesprochen werden und ursprünglich nur zur Anzeige eines ehemaligen L im Ursprungswort dienen, z. B. ラ゚ヴァー lavā statt ラヴァー ravā für engl. "lover". ル ru und ル゚ lu werden gleich ausgesprochen.
- 4Der /v/-Laut wird immer mehr in die japanische Alltagssprache integriert, genauso häufig wird dieser aber immer noch mit /b/ substituiert, da /v/ nicht zum nativ-japanischen Lautinventar gehört. So ist z. B. バージョン bājon häufiger für engl. "version" anzutreffen als das ebenso richtige ヴァージョン vājon.
Verwendung
In der Meiji-Zeit wurden Katakana noch verwendet, um Partikeln und grammatische Endungen (Okurigana) zu schreiben, besonders in offiziellen Dokumenten. Diese Rolle haben im modernen Japanisch die Hiragana übernommen.

Die häufigste Verwendung im modernen Japanisch ist die Transkription von Fremdwörtern (Gairaigo) und ausländischen Namen. So ist die allgemein gebräuchliche Bezeichnung für das Fernsehen, テレビ terebi, eine Abkürzung des französischen „télévision“. Angela Merkel wird als アンゲラ・メルケル angera·merukeru wiedergegeben.
Bei einigen Verben wird der Wortstamm in Katakana geschrieben. Diese Verben, meist aus der Jugendsprache, sind von Fremdwörtern abgeleitet. Ein Beispiel ist サボる saboru, „schwänzen“, das von „Sabotage“ abgeleitet ist.
In Kanji-Wörterbüchern werden zu besseren Übersicht die On-Lesung(en) eines Schriftzeichens in Katakana, die Kun-Lesung(en) in Hiragana angegeben. Diese Konvention beschränkt sich aber auf Wörterbücher; wenn Wörter altjapanischen oder chinesischen Ursprungs, deren Kanji heute selten oder unüblich sind, in durchgehenden Texten vorkommen, so werden sowohl On- als auch Kun-Lesungen als Hiragana geschrieben.
In Manga werden auch die vielen onomatopoetischen Ausdrücke in Katakana geschrieben (mit Ausnahmen in Hiragana).
Begriffe, die mit seltenen chinesischen Schriftzeichen geschrieben werden, also Zeichen, die nicht zu den 2136 Jōyō-Kanji gehören, werden auch oft in Katakana geschrieben. In manchen Fällen wird von einem Kompositum nur ein Schriftzeichen durch Katakana ersetzt. Üblich ist dies insbesondere bei medizinischen Begriffen. Im Wort „Dermatologie“ (皮膚科, hifuka) gilt das zweite Schriftzeichen 膚 als schwierig, weswegen hifuka üblicherweise unter Verwendung von Katakana 皮フ科 oder ヒフ科 geschrieben wird. Auch das Schriftzeichen 癌 gan, „Krebs“, wird oft in Hiragana oder Katakana geschrieben. Tiere, Pflanzen und Mineralien werden auch oft mit seltenen Kanji geschrieben, weswegen sie zur Vereinfachung oft in Katakana wiedergeben werden. Viele Sushi-Restaurants verwenden trotzdem Kanji für die einzelnen Fischarten.
Japanische Familienunternehmen verwenden oft den Nachnamen in Katakana als Firmennamen, darunter auch die heutigen Großunternehmen Suzuki (スズキ) und Toyota (トヨタ).
Katakana werden in der Schriftsprache auch als Blickfang und zur Betonung verwendet, vor allem auf Schildern. Häufige Beispiele sind ココ koko (hier), ゴミ gomi (Müll) und メガネ megane (Brille). In Werbeanzeigen werden auch einzelne Satzteile in Katakana gesetzt, zum Beispiel ヨロシク yoroshiku.
Telegramme wurden in Japan vor 1988 ebenfalls ausschließlich in Katakana geschrieben. Auch japanische Computer konnten vor der Einführung von Mehrfach-Byte-Zeichen in den 1980er Jahren nur Katakana verarbeiten.
Schriftzeichen, die über die Kanji gesetzt werden, um die Aussprache anzugeben (Furigana), sind üblicherweise in Hiragana gehalten. Wenn die Aussprache jedoch nicht japanisch, sondern englisch, chinesisch oder eine andere Sprache sein soll, werden stattdessen Katakana verwendet. So findet man zum Beispiel über der Abkürzung JR (Japan Railways) klein den Schriftzug ジェイアール (jei āru), der die Aussprache des Kürzels angibt.
Eine Reihe von chinesischen Gerichten, die erst im 20. Jahrhundert nach Japan kamen, wird zwar mit chinesischen Schriftzeichen geschrieben, die Aussprache entspricht aber nicht der sinojapanischen On-Lesung, sondern der kantonesischen oder der Hochchinesischen. Auf den Verpackungen im Supermarkt sind die Namen der Produkte meist in chinesischen Schriftzeichen geschrieben, aber die Lesung zusätzlich in Katakana angegeben. Aus Bequemlichkeit lässt man oft die Schriftzeichen weg und schreibt diese Worte nur in Katakana:
- ウーロン茶 (烏龍茶), ūroncha, von Hochchinesisch wūlóng chá (烏龍茶).
- チャーハン (炒飯), chāhan, vom allgemein Chinesischen, Gebratener Reis – Chǎofàn (炒飯).
- チャーシュー (叉焼), chāshū, von Kantonesisch Chasiu – auch Char siu (叉燒), gegrilltes Schweinefleisch nach kantonesischer Art.
- シューマイ (焼売), shūmai, von Kantonesisch Siumaai – auch Siu maai (燒賣), eine Dim-Sum-Variante.
- ラーメン (拉麺), rāmen, von Hochchinesisch Lāmiàn (拉麵), handgezogene Weizennudeln.
In Manga werden Katakana auch manchmal verwendet, um zu verdeutlichen, dass etwas mit einem ausländischen oder anderweitig seltsamen Akzent gesagt wird. So könnte ein Roboter コンニチワ (konnichi wa) statt der üblichen Schreibung こんにちは in Hiragana sagen. Die eckige Form der Katakana soll dabei einen optischen Eindruck von der Aussprache geben.
In der Nachkriegszeit war es Mode, Kindern, besonders Mädchen, Vornamen in Katakana-Schreibung zu geben, so dass ältere Damen öfters Namen in Katakana tragen. Dabei wurden auch ausländische Namen, die sich im Japanischen gut anhören, wie マリア Maria und エリカ Erika verwendet.
Katakana werden in der traditionellen japanischen Musik für die Schreibung der Noten verwendet, zum Beispiel in der Tozan-Schule der Shakuhachi, und in Sankyoku-Ensembles, bestehend aus Koto, Shamisen und Shakuhachi.
Orthographie
Die Katakana-Orthographie unterscheidet sich leicht von der bei Hiragana üblichen. Bei Katakana ist zur Anzeige von Vokallängen der Längungsstrich (ー) Chōonpu vorgesehen, in Hiragana wird stattdessen ein zweiter Vokal gesetzt. Diese Wörterbuchregelung wird allerdings im täglichen Gebrauch nicht so genau genommen. Beispielsweise wird das Wort Rāmen meist in Hiragana mit Längungsstrich geschrieben (らーめん). Umgekehrt werden, obwohl Katakana für Lehnworte vorgesehen sind, manchmal auch japanische Wörter in Katakana notiert. Langvokale werden dann entweder wie in Hiragana durch zusätzlichen Vokal dargestellt (ロウソク rōsoku „Kerze“, Hiragana ろうそく, Kanji 蝋燭) oder mit Längungsstrich (ローソク). Diese Schreibweise wird mitunter auch für die Vokalkombination ei /ɛɪ/ verwendet, um deren häufige Aussprache als langes e /eː/ abzubilden (zum Beispiel ケータイ kētai „Mobiltelefon“, eigentlich keitai, Hiragana けいたい, Kanji 携帯).
Wie in den obigen Beispielen zu sehen, werden lange Vokale in der Hepburn-Transkription mit einem Makron (¯) wiedergegeben. Andere Transkriptionssysteme verwenden einen Zirkumflex (ˆ) oder verdoppeln den Vokal.
Bei senkrechter Schreibung (tategaki) ist der Längungsstrich ebenfalls vertikal. In dieser Form ist er auch gut vom Schriftzeichen 一 (ichi, „eins“) zu unterscheiden, das sowohl in waagerechter als auch in senkrechter Schreibweise ein waagerechter Strich ist.
Wie bei den Hiragana zeigt ein kleines tsu (ッ), sokuon genannt, die Gemination des Anfangskonsonanten der nachfolgenden Silbe an. In der Transkription wird der Konsonant verdoppelt (bei sh nur das s, also ssh, bei tsu nur das t, also ttsu, und ch wird zu tch oder bisweilen cch). Das englische Wort „bed“ wird in Katakana ベッド geschrieben und als beddo zurücktranskribiert. Wie das Beispiel zeigt, können in (Katakana-)Schreibweisen ausländischer Fremdworte auch solche Konsonanten geminiert vorkommen, bei denen das im Japanischen sonst nicht möglich ist (wie etwa d).
Wiedergabe ausländischer Fremdworte
Wie Hiragana können auch Katakana nur den Lautvorrat des Japanischen wiedergeben, der sich von dem anderer Sprachen deutlich unterscheiden kann. Daher ist die Aussprache von Fremdworten in Katakana oft nur eine Annäherung an die Originalaussprache und es dementsprechend nicht immer einfach, aus einer Katakana-Schreibung auf das Originalwort zurückzuschließen. Zwar haben sich im Laufe der Zeit einige typische Muster herausgebildet, aber auch eine Reihe von Begriffen in abweichenden Formen etabliert; die phonetisch sehr ähnlichen „towel“ und „tower“ beispielsweise werden zur Unterscheidung als タオル taoru bzw. タワー tawā wiedergegeben. Vor allem konsonantenreiche Silben sind problematisch; hier müssen Sprossvokale eingefügt werden, wie etwa in フランクフルト Furankufuruto („Frankfurt“). Lehnworte, die (oft wegen der Sprossvokale) zu viele Silben enthalten, werden im Japanischen gern abgekürzt, so wird „sexual harassment“ zu セクハラ sekuhara (statt セクシャル・ハラスメント sekusharu harasumento).
Eine ganze Reihe weiterer Vokale und Konsonanten lässt sich in Katakana nur schwer umsetzen, beispielsweise:
- Das Japanische kennt nur einen liquiden Konsonanten, daher müssen sowohl „r“ als auch „l“ mit Silben derselben Reihe wiedergegeben werden, deren Anfangskonsonant als r transkribiert und häufig ungefähr als [ɺ] oder [ɾ] realisiert wird.
- Die deutschen Umlaute „ä“, „ö“ und „ü“ haben im Japanischen gar keine Entsprechung. Der als e transkribierte japanische Vokal ähnelt allerdings eher einem deutschen „ä“ als einem (langen) deutschen „e“ und wird daher zu dessen Wiedergabe herangezogen. Auch beim „ö“ hilft man sich mit „e“ (ケーラー kērā für Köhler), oder mit „u“ (パスツール pasutsūru für „Pasteur“). Das „ü“ wird durch Silben mit kleinem yu (zum Beispiel リュ ryu in リュプケ ryupuke für „Lübke“) approximiert.
- Den stimmlosen velaren oder uvularen Frikativ, also den „Ach-Laut“ des Deutschen, gibt es im Japanischen nicht. Er wird in der Katakana-Transkription als Kombination aus Sokuon (ッ) und Silben der h-Reihe dargestellt. Der Komponist Johann Sebastian Bach wird beispielsweise ヨハン・ゼバスティアン・バッハ Yohan Zebasutian Bahha und der Mediziner Robert Koch ロベルト・コッホ Roberuto Kohho geschrieben. Der stimmlose palatale Frikativ („Ich-Laut“) hingegen ist eine häufige Realisation des Konsonanten der Silbe hi, weswegen beispielsweise der Name Friedrich zu フリートリヒ Furīdorihi wird. Mit den von dieser Silbe abgeleiteten Silben hya, hyu und hyo lassen sich „Ich-Laute“ darstellen, denen ein anderer Vokal als „i“ folgt (etwa in ミヒャエル Mihyaeru „Michael“). Folgt dem „Ich-Laut“ ein „e“, verwendet man traditionell die Silbe he (ミュンヘン Myunhen „München“, メルヘン meruhen für „Märchen“), da es die Silbe hye nicht gibt.
- Weitere Beispiele für die Schwierigkeiten bei der Transkription von Namen nach Katakana sind „Chruschtschow“ フルシチョフ (Furushichofu), „Ali Khamenei“ アリー・ハーメネイー (Arī Hāmeneī), Itzhak Perlman イツハク・パールマン (Itsuhaku Pāruman).
Für Japaner hat die Transkription von Namen allerdings einen entscheidenden Vorteil: Die Katakana geben eine für sie leicht nachvollziehbare Aussprache vor, selbst wenn diese weit entfernt vom Original liegt. Namen in lateinischen Buchstaben sind dagegen alles andere als eindeutig: Als Europäer entwickelt man zwar ein gewisses Gefühl dafür, ob ein Name englisch, französisch, deutsch, polnisch, spanisch oder wie auch immer auszusprechen ist und wie es ungefähr klingen muss, doch für Japaner stellt das eine Hürde dar, die ähnlich hoch ist wie Namen in chinesischen Schriftzeichen für Europäer.
Da es keine Leerzeichen in der japanischen Schrift gibt, wird zur Trennung von Wörtern in einem Katakana-Block stattdessen ein Mittelpunkt (・) gesetzt, japanisch nakaguro (中黒) oder nakaten (中点). Ein Beispiel ist die Trennung von Vorname und Nachname bei ausländischen Namen. Bindestriche werden, wohl um Verwechslungen mit dem Chōonpu zu vermeiden, zu Gleichheitszeichen (=), wie etwa in アンネグレート・クランプ=カレンバウアー Annegurēto Kurampu-Karenbauā (Annegret Kramp-Karrenbauer).
Strichreihenfolge

Geschichte

Die Katakana wurden in der frühen Heian-Zeit aus den Man’yōgana entwickelt, die ursprünglich dazu dienten, die Aussprache eines Zeichens in Kanbun-Texten zu markieren. Bei Zeichen, die sich als Markierung einer bestimmten Aussprache etabliert hatten, wurden dann zur Vereinfachung einzelne Elemente weggelassen. So entstand aus 加, „addieren“, gelesen ka, durch Weglassen des Elements 口 das Katakana カ.
Erst später ging man dazu über, Schriftzeichen in der im Japanischen üblichen Wortreihenfolge zu schreiben und auch die Flexionsendungen an Verben anzuhängen. Das Chinesische kennt als isolierende Sprache keine Flexion.
Zeichensätze
Katakana existieren in den meisten Schriftsätzen in voller (全角 zenkaku, engl. full-width) und in halber Breite (半角 hankaku, engl. half-width). Die Katakana in halber Breite wurden 1969 mit dem 8bit-JIS X 0201-Standard eingeführt, die Katakana stehen dabei im erweiterten Bereich ab 0x80, jenseits der ASCII-Zeichen. Da im erweiterten Bereich nur Platz für 128 Zeichen war, wurden von der japanischen Schrift nur die Katakana implementiert. Katakana wurden traditionell wie chinesische Schriftzeichen in quadratischen Blöcken (Geviert) geschrieben. Die damaligen Schriftsätze sahen jedoch eine feste Zeichenbreite von einem Halbgeviert vor, weswegen ein Katakana-Schriftsatz entwickelt wurde, der nur halb so breit war. Damit war es möglich, mit einem 8bit-Schriftsatz Japanisch zu schreiben, auch wenn auf Hiragana und Kanji verzichtet werden musste.
In den späten 1970er Jahren wurden dann Zwei-Byte-Schriftsätze wie JIS X 0208 entwickelt, die es mit ihrem Zeichenraum von über 65.000 Zeichen möglich machten, Hiragana, Katakana und Kanji zu schreiben und damit die japanische Schrift vollständig digital darzustellen. Außerdem erlaubten die Schriftsätze Zeichen in der vollen Geviert-Breite. JIS X 0208 führte nun einen zweiten Zeichenraum für Katakana in der vollen Breite ein. Diese Katakana waren nicht nur im Schriftsatz doppelt so breit, sondern auch in der Digitalisierung, da sie auf zwei Byte gespeichert wurden.
Diese geschichtliche Entwicklung ist auch der Grund, warum es Half-width-Katakana, aber keine Half-width-Hiragana gibt.
Trotz aller Bemühungen, diese eigentlich überflüssige Dopplung abzuschaffen sind Half-width-Katakana immer noch in verschiedenen Systemen in Verwendung. Die Titelanzeige bei MiniDiscs verwendet beispielsweise eine dem JIS X 0201 ähnliche Kodierung und lässt ausschließlich ASCII und halbbreite Katakana zu. Half-width-Katakana finden sich auch in elektronischen Registrierkassen und in DVD-Untertiteln. Die meisten gebräuchlichen Japanisch-Zeichensätze wie EUC-JP (s. Extended Unix Code), Unicode und Shift-JIS bieten sowohl half-width als auch full-width Katakana an. Der in E-Mails und im Usenet übliche ISO-2022-JP (s. ISO/IEC 2022) hat dagegen nur die Zwei-Byte-Katakana.
Unicode
Im Unicode belegen die normalbreiten Katakana den Unicodeblock Katakana (U+30A0 bis U+30FF):
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 30A | ゠ | ァ | ア | ィ | イ | ゥ | ウ | ェ | エ | ォ | オ | カ | ガ | キ | ギ | ク |
| 30B | グ | ケ | ゲ | コ | ゴ | サ | ザ | シ | ジ | ス | ズ | セ | ゼ | ソ | ゾ | タ |
| 30C | ダ | チ | ヂ | ッ | ツ | ヅ | テ | デ | ト | ド | ナ | ニ | ヌ | ネ | ノ | ハ |
| 30D | バ | パ | ヒ | ビ | ピ | フ | ブ | プ | ヘ | ベ | ペ | ホ | ボ | ポ | マ | ミ |
| 30E | ム | メ | モ | ャ | ヤ | ュ | ユ | ョ | ヨ | ラ | リ | ル | レ | ロ | ヮ | ワ |
| 30F | ヰ | ヱ | ヲ | ン | ヴ | ヵ | ヶ | ヷ | ヸ | ヹ | ヺ | ・ | ー | ヽ | ヾ | ヿ |
Die Katakana in halber Breite sind im Block von U+FF65 bis U+FF9F kodiert:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FF6 | ⦆ | 。 | 「 | 」 | 、 | ・ | ヲ | ァ | ィ | ゥ | ェ | ォ | ャ | ュ | ョ | ッ |
| FF7 | ー | ア | イ | ウ | エ | オ | カ | キ | ク | ケ | コ | サ | シ | ス | セ | ソ |
| FF8 | タ | チ | ツ | テ | ト | ナ | ニ | ヌ | ネ | ノ | ハ | ヒ | フ | ヘ | ホ | マ |
| FF9 | ミ | ム | メ | モ | ヤ | ユ | ヨ | ラ | リ | ル | レ | ロ | ワ | ン | ゙ | ゚ |
Darüber hinaus gibt es den Code-Bereich U+32D0 bis U+32FE, in dem alle Katakana bis auf ン in eingekreister Form vorhanden sind.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 32D | ㋐ | ㋑ | ㋒ | ㋓ | ㋔ | ㋕ | ㋖ | ㋗ | ㋘ | ㋙ | ㋚ | ㋛ | ㋜ | ㋝ | ㋞ | ㋟ |
| 32E | ㋠ | ㋡ | ㋢ | ㋣ | ㋤ | ㋥ | ㋦ | ㋧ | ㋨ | ㋩ | ㋪ | ㋫ | ㋬ | ㋭ | ㋮ | ㋯ |
| 32F | ㋰ | ㋱ | ㋲ | ㋳ | ㋴ | ㋵ | ㋶ | ㋷ | ㋸ | ㋹ | ㋺ | ㋻ | ㋼ | ㋽ | ㋾ |
Katakana für die Ainu-Sprache
Auch die Ainu-Sprache wird mit Katakana geschrieben. In dieser Sprache können Silben auf verschiedene Konsonanten enden. Um diese zu schreiben wird der Endkonsonant durch ein halbhohes Zeichen aus der u-Spalte geschrieben, der Vokal bleibt dabei stumm. Die Silbe up wird demnach ウㇷ゚ (u mit kleinem pu) geschrieben. In Unicode sind für die Ainu-Sprachunterstützung die Zeichen im phonetischen Erweiterungsblock für Katakana reserviert (U+31F0 bis U+31FF), der auch halbhohe Katakana enthält, die nicht auf -u enden.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 31F | ㇰ | ㇱ | ㇲ | ㇳ | ㇴ | ㇵ | ㇶ | ㇷ | ㇸ | ㇹ | ㇺ | ㇻ | ㇼ | ㇽ | ㇾ | ㇿ |
Weblinks
- The Unicode Standard: Version 11.0 – Core Specification. 18.4 Hiragana and Katakana (ab S. 720 Beschreibung der Kana in Unicode 11.0; PDF-Datei; 799 kB; englisch)
- Lesen und Schreiben von Katakana | Japanisch lernen für Anfänger auf YouTube, 4. September 2019, abgerufen am 2. März 2020.
Einzelnachweise
- ↑ Thomas E. McAuley: Language change in East Asia. Routledge, 2001, ISBN 0-7007-1377-8, S. 90.
- ↑ a b c Mombu-Kagaku-shō – MEXT: 外来語の表記 – Darstellung von Lehnwörtern. (Memento vom 18. November 2019 im Internet Archive) In: www.mext.go.jp, abgerufen am 15. September 2020. (japanisch).
- ↑ 「いろは と アイウエオ」. (Memento vom 27. Mai 2012 im Webarchiv archive.today) In: members.jcom.home.ne.jp, abgerufen am 15. September 2020 (japanisch).
- ↑ 伊豆での収穫 日本国語学史上比類なき変体仮名. (Memento vom 24. Juni 2011 im Internet Archive) In: www.geocities.jp, abgerufen am 15. September 2020. (japanisch).
- ↑ 和ヰスキーバー AKASAKA – 国産ウイスキーと燻製つまみ – Japanese Whiskey & Smoked Foods – Whiskyは「ヰスキー」. In: waisky-smoke.ldblog.jp. 28. Januar 2011, abgerufen am 16. September 2020 (japanisch, Blog zum japanischen Whiskey und geräucherte Imbiss).
- ↑ a b Wolfgang Hadamitzky: Kana-Transkriptionstafeln. In: www.hadamitzky.de. Abgerufen am 15. September 2020.
- ↑ a b Was mache ich aus Lauten, die im Japanischen so nicht existieren? In: www.japanisch-grund-und-intensivkurs.de. Abgerufen am 15. September 2020.
- ↑ a b c Katakana. In: nihongoichiban.com. Nihongo Ichiban, abgerufen am 1. Januar 2020 (englisch, Katakana Tabelle).
- ↑ Yu Sato: Einführung in die japanische Sprachwissenschaft. (Memento vom 26. Juni 2013 im Internet Archive) PDF-Datei; 247 kB, In: www.tufs.ac.jp, abgerufen am 15. September 2020 (japanisch).
- ↑ 大辞林 特別ページ – 現代日本語の拍の音声記号表(五十音図による). In: daijirin.dual-d.net. Abgerufen am 15. September 2020 (japanisch, Sanseido Dual Dictionary – Daijirin – Neuzeitliche Erweiterung der Lauttabelle).
- ↑ a b Hyōjun-Shiki Rōmaji tsuzuri inʼyō – 標準式ローマ字つづり―引用 (Memento vom 24. September 2015 im Internet Archive), Standardformel Romaji-Schreibweise. In: www.halcat.com, abgerufen am 15. September 2020. (japanisch).
- ↑ Timothy J. Vance: The Sounds of Japanese
- ↑ Chirag Bharadwa, Cornell University 11. Januar 2016: Japanese Language and Culture – An Introduction to Katakana (Memento vom 29. Dezember 2007 im Internet Archive), PDF-Datei; 9,3 MB, In: www.cs.princeton.edu, abgerufen am 16. Januar 2016. (englisch)
- ↑ 英国規格(BS 4812:1972)―要約 – British Standard(BS 4812:1972)–Summary. In: halcat.com. Archiviert vom am 3. Juni 2013; abgerufen am 24. Januar 2011 (japanisch).
- ↑ ヶ – Elektronischer Wörterbucheintrag. In: jisho.org. Abgerufen am 15. September 2020 (englisch, japanisch, EN<->JA-Wörterbuch).
- ↑ y's Japanese – A bilingual blog on Learning Japanese – Bidakuon / 鼻濁音. (Memento vom 28. Juni 2018 im Internet Archive) In: ysjapanese.wp-x.jp, abgerufen am 15. September 2020 (englisch, japanisch)
- ↑ silverdoi: Why が is pronounced "nga"? In: hinative.com. 25. Januar 2017, abgerufen am 15. September 2020 (englisch, Blog-Frage auf HiNative.com).
- ↑ lessthanpandaさん: 日本語の「か゚行」の存在を知っていますか? – Was ist über die Existenz der K-Reihe mit Handakuten bekannt? In: matome.naver.jp. Naver, abgerufen am 15. September 2020 (japanisch, Blog-Beitrag auf matome.naver.jp).
- ↑ メモモモモ – カ行の半濁点カ゜キ゜ク゜ケ゜コ゜は普通?だった – MEMOMOMOMO – Werden die Katakana der k-Reihe mit Handakuten verwendet? Heute nicht, damals schon. In: memomo2.blogspot.com. 4. März 2016, abgerufen am 15. September 2020 (japanisch, Blog-Beitrag auf memomo2.blogspot.com).
- ↑ NAKAYAMA Kazuo (中山和男 – 音声学) & YAMAGUCHI Junko (山口純子 – 英語科教): 日本語話者における米語歯茎摩擦音[s]と[∫]の 調音混同の理論的考察 – Amerikanische gingivale Frikative (s) und (∫) in Japanisch – Theoretische Betrachtung der artikulatorischen Schwierigkeiten. (PDF; 756 kB) In: www2.lib.yamagata-u.ac.jp. 1. Januar 1999, abgerufen am 15. September 2020 (japanisch).
- ↑ Proposal to Encode MissingJapanese Kana(PDF-Datei; 5,0 MB) In: unicode.org/L2, abgerufen am 10. Oktober 2020 (englisch, japanisch)
- ↑ Unicode Consortium: UTC Minutes #162. In: unicode.org. Unicode Consortium, 14. April 2020, abgerufen am 10. November 2020 (englisch).
- ↑ Japanese National Body Contribution on Small Kana Characters – ISO/IEC JTC 1/SC 2 N 4523 – Coded character sets Secretariat: JISC (Japan). (PDF; 2,8 MB) In: www.unicode.org. 1. April 2017, abgerufen am 15. September 2020 (englisch).
- ↑ Ryusei Yamaguchi: Proposal to add Kana small letters – L2/16-354. (PDF; 1,8 MB) In: www.unicode.org. 7. November 2016, abgerufen am 15. September 2020 (englisch).